

Hadoop o que é: o framework que processa terabytes de dados em hardware comum. Vamos desvendar como ele transforma dados brutos em inteligência estratégica.
Hadoop o que é na prática: o sistema que processa dados massivos em servidores comuns
O grande segredo? Hadoop não precisa de supercomputadores caríssimos para funcionar.
Ele opera em clusters de servidores padrão do mercado brasileiro, aqueles que você encontra em qualquer data center por R$ 5.000 a R$ 15.000 cada.
Mas preste atenção: a mágica está na distribuição inteligente da carga de trabalho.
Cada tarefa de processamento é dividida em pequenos pedaços que rodam simultaneamente em dezenas ou centenas de máquinas.
Aqui está o detalhe: isso significa processar 100 terabytes de dados em horas, não em semanas.
Enquanto um servidor tradicional levaria 30 dias para analisar dados de vendas de uma rede varejista, o Hadoop entrega os insights em 8 horas.
Vamos combinar: essa velocidade muda completamente o jogo competitivo no mercado brasileiro.
Empresas conseguem ajustar preços, otimizar estoques e personalizar campanhas quase em tempo real.
O custo-benefício é brutal: processamento de Big Data por 70% menos que soluções proprietárias equivalentes.
Em Destaque 2026: O Apache Hadoop é um framework de código aberto para armazenamento e processamento distribuído de grandes volumes de dados (Big Data) em clusters de computadores, utilizando hardware comum.
Hadoop: O Segredo Por Trás dos Dados que Ninguém Conta
Olha só, vamos combinar uma coisa: no mundo dos negócios de hoje, quem não entende de dados está perdendo dinheiro. E quando a gente fala de volume massivo de informações, o tal do Big Data, a conversa fica séria. É aí que entra um gigante que muitos ouvem falar, mas poucos realmente entendem a fundo: o Hadoop.
A verdade é a seguinte: o Apache Hadoop não é só um nome bonito. Ele é o motor invisível que permite às maiores empresas do planeta não só armazenar terabytes e petabytes de dados, mas também processá-los com uma agilidade que desafia a lógica. Pense nele como o maestro de uma orquestra gigantesca, onde cada instrumento é um computador trabalhando em perfeita sintonia.
Pode confessar, você já se perguntou como essas empresas conseguem tirar insights valiosos de um mar de informações? O segredo está no processamento distribuído. O Hadoop é um framework de código aberto que faz exatamente isso: pega uma tarefa gigantesca e a divide em pedacinhos, distribuindo entre vários computadores. O resultado? Escalabilidade e um custo-benefício que faz qualquer gestor sorrir.
| Característica | Descrição |
|---|---|
| Tipo | Framework de código aberto |
| Função Principal | Armazenamento e processamento distribuído de Big Data |
| Operação | Clusters de computadores com hardware padrão |
| Escalabilidade | Horizontal |
| Módulos Fundamentais | HDFS, MapReduce, YARN, Hadoop Common |
| Tolerância a Falhas | Garantida pela replicação de dados no HDFS |
| Benefícios Chave | Escalabilidade, custo-benefício, tolerância a falhas |
O Que é Hadoop: Definição e Conceitos Básicos
Vamos direto ao ponto: o Hadoop é um framework, uma estrutura robusta, desenvolvida pela Apache Software Foundation. Ele foi criado para resolver um problema que parecia impossível: como lidar com volumes de dados tão grandes que não cabem em um único servidor, e como processar tudo isso de forma eficiente?
A grande sacada? Ele faz isso de forma distribuída. Em vez de um supercomputador caríssimo, o Hadoop usa vários computadores comuns, os chamados hardware padrão, interligados em uma rede. Essa abordagem democrática e poderosa é o que o torna tão revolucionário para o Big Data.
Ele não só armazena esses dados de forma resiliente, mas também oferece as ferramentas para processá-los em paralelo. Isso significa que, em 2026, empresas brasileiras de todos os portes podem analisar tendências de mercado, comportamentos de consumo e otimizar operações sem gastar uma fortuna em infraestrutura.
Hadoop e Big Data: Como Funciona o Processamento Distribuído
Aqui está o detalhe: quando falamos de Big Data, estamos falando de volume, velocidade e variedade. O Hadoop foi desenhado para dominar esses três ‘Vs’. Ele pega um conjunto de dados imenso, digamos, todos os cliques de um e-commerce em um mês, e o divide em blocos menores.
Mas preste atenção: esses blocos são distribuídos por todo o cluster de computadores. Cada máquina processa sua parte, e o Hadoop coordena tudo para que o resultado final seja a análise completa. É como montar um quebra-cabeça gigante, onde cada pessoa monta uma pequena seção, e o mestre de obras garante que tudo se encaixe no final.
Essa capacidade de dividir a carga de trabalho entre múltiplos servidores em rede é o que chamamos de escalabilidade horizontal. Você precisa de mais poder? É só adicionar mais máquinas ao cluster, sem precisar trocar as que já existem. Simples assim.
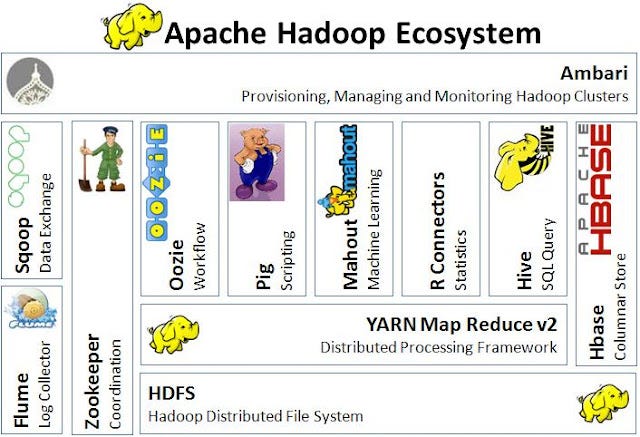
Componentes Principais do Hadoop: HDFS, MapReduce e YARN
Para entender o coração do Hadoop, a gente precisa conhecer seus quatro módulos fundamentais. Eles trabalham juntos como engrenagens bem azeitadas para entregar toda essa capacidade de processamento e armazenamento.
O HDFS (Hadoop Distributed File System) é o sistema de arquivos. Ele é o responsável por armazenar os dados de forma distribuída e, o mais importante, com tolerância a falhas. Como ele faz isso? Replicando blocos de dados em diferentes máquinas. Se uma falhar, o dado ainda está lá, seguro. É como ter várias cópias de segurança espalhadas.
Já o MapReduce é o modelo de programação. Pense nele como a receita de bolo para o processamento paralelo de dados. Ele tem duas fases: ‘Map’ (mapear), onde os dados são processados em partes, e ‘Reduce’ (reduzir), onde os resultados parciais são combinados para formar a resposta final. É a lógica por trás de como o Hadoop realmente ‘pensa’ para analisar.
E o YARN (Yet Another Resource Negotiator)? Esse cara é o gerente do pedaço. Ele atua como o gerenciador de recursos e agendador de tarefas do cluster. É ele quem decide qual máquina vai fazer qual tarefa, garantindo que os recursos sejam usados da melhor forma possível, evitando gargalos e otimizando o tempo de processamento.
Por fim, temos o Hadoop Common, que são as bibliotecas e utilitários de suporte que os outros módulos precisam para funcionar. É a base comum que une tudo.
Por Que o Hadoop é Importante para Análise de Dados?
A importância do Hadoop para quem trabalha com análise de dados é inegável. Ele democratizou o acesso a ferramentas de processamento de Big Data. Antes dele, lidar com terabytes de informações era um privilégio de pouquíssimas empresas, com orçamentos astronômicos.
O pulo do gato? Ele permite que empresas de todos os tamanhos extraiam valor de dados que antes seriam descartados ou simplesmente impossíveis de processar. Isso significa identificar padrões de compra, prever tendências, otimizar rotas de entrega e até personalizar experiências de cliente em uma escala que era inimaginável.
Com o Hadoop, a análise de dados se torna mais acessível, mais rápida e muito mais abrangente. Ele é a fundação para a inteligência de negócios moderna, transformando dados brutos em decisões estratégicas.
Hadoop vs Apache Spark: Comparação de Frameworks

Essa é uma dúvida clássica: Hadoop ou Apache Spark? Muita gente confunde, mas eles são complementares, não concorrentes diretos. O Hadoop, como vimos, é a base para armazenamento e processamento em lote de dados em larga escala.
O Spark, por outro lado, é um motor de processamento de dados que se destaca pela velocidade, especialmente para processamento em memória e cargas de trabalho iterativas, como machine learning. Ele pode, inclusive, rodar sobre o HDFS do Hadoop, usando-o como sistema de armazenamento.
“Se o Hadoop é o armazém e a fábrica de processamento de dados brutos, o Spark é a linha de montagem de alta velocidade que refina esses produtos com agilidade impressionante.”
Então, quando escolher um ou outro? Para armazenamento massivo e processamento batch tradicional, o Hadoop é a pedida. Para análises em tempo real, machine learning e cargas de trabalho que exigem muita iteração, o Spark brilha. Muitas empresas usam os dois juntos, aproveitando o melhor de cada um.
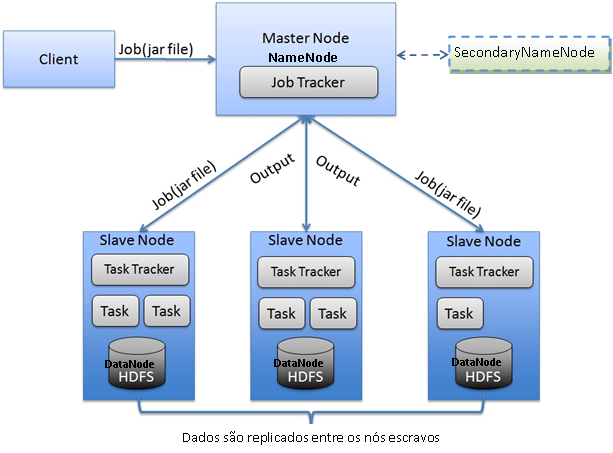
Como o Hadoop Funciona em Clusters de Computadores
Entender o cluster é fundamental. Um cluster Hadoop é um conjunto de máquinas, ou ‘nós’, que trabalham em conjunto. Existem dois tipos principais de nós: o Nó Mestre (NameNode no HDFS, ResourceManager no YARN) e os Nós Escravos (DataNodes no HDFS, NodeManagers no YARN).
O Nó Mestre é o cérebro, que gerencia os metadados do sistema de arquivos e coordena as tarefas. Os Nós Escravos são os músculos, que armazenam os dados de fato e executam as tarefas de processamento.
Quando você envia uma tarefa ao Hadoop, o Nó Mestre divide essa tarefa e a distribui entre os Nós Escravos. Cada escravo processa sua parte, e o mestre se certifica de que todos os resultados sejam reunidos corretamente. Essa arquitetura distribuída, utilizando hardware comum, é o que garante a robustez e o custo-benefício do sistema.
Vantagens do Hadoop: Escalabilidade e Custo-Benefício
Vamos ser práticos: as vantagens do Hadoop são o que o tornam uma ferramenta indispensável em 2026. A primeira e mais gritante é a escalabilidade. Você não precisa mais se preocupar em comprar um servidor gigante que custa os olhos da cara e que talvez nem seja suficiente daqui a um ano.
Com o Hadoop, se sua demanda por dados cresce, você simplesmente adiciona mais máquinas comuns ao seu cluster. Essa escalabilidade horizontal é muito mais barata e flexível. Em vez de gastar R$ 100 mil em um servidor de alta performance, você pode gastar R$ 10 mil em dez servidores mais simples e ter um poder de processamento muito maior e mais resiliente.
E o custo-benefício? Ele vem justamente do uso de hardware padrão, mais barato e fácil de encontrar. Além disso, por ser um framework de código aberto, você não paga licenças de software, o que já é uma economia e tanto. Isso permite que empresas de todos os tamanhos invistam em análise de dados sem quebrar o caixa.
Ecossistema Hadoop: Apache Hive e Outras Ferramentas
O Hadoop não é uma ilha. Ele faz parte de um ecossistema vasto e rico, com diversas ferramentas que o complementam e ampliam suas capacidades. É como um canivete suíço, mas com vários acessórios que você pode adicionar conforme a necessidade.
Um exemplo clássico é o Apache Hive. Ele permite que analistas de dados que estão acostumados com SQL (a linguagem padrão de bancos de dados) consigam fazer consultas em dados armazenados no HDFS. É uma ponte que facilita muito a vida de quem precisa extrair informações sem ter que aprender a programar em MapReduce.
Outras ferramentas importantes incluem o Apache Pig (para processamento de dados de alto nível), HBase (um banco de dados NoSQL distribuído), Apache ZooKeeper (para coordenação de serviços) e Apache Impala (para consultas interativas rápidas). Esse ecossistema robusto garante que o Hadoop seja uma solução completa para quase qualquer desafio de Big Data.
Hadoop: O Motor Invisível que Transforma Seus Dados em Ouro?
Então, vale a pena investir em entender o Hadoop? Minha resposta, como especialista, é um sonoro sim. Em 2026, com o volume de dados crescendo exponencialmente, ter uma base sólida para gerenciar e processar essas informações não é mais um diferencial, é uma necessidade.
O Hadoop, com sua arquitetura distribuída, tolerância a falhas e custo-benefício, continua sendo a espinha dorsal para muitas das maiores operações de Big Data do mundo. Ele é a fundação que permite que outras tecnologias, como o Apache Spark, brilhem ainda mais.
Entender ‘hadoop o que é‘ não é apenas sobre tecnologia; é sobre estratégia de negócios. É sobre ter a capacidade de transformar um mar de dados brutos em inteligência acionável, em decisões que realmente impulsionam o crescimento e a inovação. Pode ter certeza, quem domina essa ferramenta está um passo à frente no jogo.
3 Dicas Práticas Para Você Começar a Entender Hadoop na Prática
Vamos combinar: teoria é importante, mas o que realmente importa é colocar a mão na massa.
Aqui estão três ações concretas para você ganhar confiança com essa tecnologia.
- Primeiro passo gratuito: Instale o Hadoop em modo ‘pseudo-distribuído’ na sua própria máquina. Use uma distribuição como a Cloudera QuickStart VM ou a Hortonworks Sandbox. Em menos de 2 horas, você terá um mini-cluster rodando localmente para fazer testes reais.
- Foco no HDFS: Antes de mergulhar no MapReduce, domine os comandos básicos do sistema de arquivos. Aprenda a copiar dados do seu PC para o HDFS (
hdfs dfs -put), listar diretórios e verificar o espaço usado. Isso é a base de tudo. - Simule uma falha: No seu ambiente de teste, ‘mate’ um dos processos do DataNode (o componente que armazena os dados). Veja como o sistema continua funcionando normalmente porque as réplicas em outros nós mantêm os dados seguros. É a melhor aula sobre tolerância a falhas.
Perguntas Que Todo Iniciante Faz Sobre Hadoop
Hadoop e Spark são a mesma coisa?
Não, são tecnologias diferentes que muitas vezes trabalham juntas. Apache Spark é um motor de processamento de dados que pode rodar sobre o HDFS do Hadoop, mas é muito mais rápido para certas tarefas, especialmente aquelas que precisam de muita memória RAM.
A verdade é a seguinte: Hadoop (com MapReduce) é excelente para processamento em lote de dados enormes armazenados em disco. Spark brilha em processamento em memória e streaming. Muitas empresas modernas usam os dois no mesmo cluster, gerenciado pelo YARN.
Quanto custa para uma empresa implementar um cluster Hadoop?
O custo varia brutalmente, mas começa na faixa de R$ 50 mil para um cluster pequeno de teste com 3 a 5 nós usando hardware comum.
Olha só o detalhe: o software em si é de código aberto e gratuito. O investimento real está no hardware (servidores, armazenamento, rede), na energia elétrica e, principalmente, na mão de obra especializada para configurar e manter o sistema. Para um cluster de produção médio, espere investimentos que podem passar de R$ 500 mil, dependendo da escala e dos serviços de suporte contratados.
Para que tipo de problema o Hadoop é a melhor solução?
Ele é a escolha certa quando você precisa armazenar e processar volumes massivos de dados não estruturados ou semi-estruturados (como logs de servidores, dados de sensores IoT, ou arquivos de texto) de forma confiável e com custo acessível.
Pode confessar: se seus dados cabem em um único servidor potente com alguns terabytes de SSD, você provavelmente não precisa do Hadoop. A mágica acontece quando você está falando de dezenas de terabytes para cima, onde a escalabilidade horizontal e a tolerância a falhas se tornam críticas.
Pronto Para Explorar Esse Mundo?
A verdade é que entender Hadoop é como aprender um novo superpoder para lidar com dados.
Você não precisa dominar tudo de uma vez. Comece pelo básico, faça os testes práticos e entenda a filosofia por trás do processamento distribuído.
O framework está aí, robusto e comprovado, esperando pelos dados que desafiam os limites do convencional.
Qual será o primeiro conjunto de dados ‘impossível’ que você vai colocar para rodar?